Reading-Notes
Linear Regression
Introduction to linear regression
Linear regression is a model that assumes a linear relationship between the input variables (x) and the single output variable (y).
x: independent variable (explanatory variable)
y: dependent variable (response variable)
x variable is used to predict the y variable.

Running Linear regression in Python scikit-Learn
You can do linear regression using numpy, scipy, stats model and sckit learn.
- import libraries.

- download data set.
- convert data to pandas data frame.
- determine dependent and independent variables.
- import linear regression from sci-kit learn module.

- make a plot of your data.
- create a line that takes most of the points on the plot.
- notice the relationship between variables.
Important functions to keep in mind while fitting a linear regression model are:
lm.fit() -> fits a linear model
lm.predict() -> Predict Y using the linear model with estimated coefficients
lm.score() -> Returns the coefficient of determination (R^2). A measure of how well observed outcomes are replicated by the model, as the proportion of total variation of outcomes explained by the model.
### How to do train-test split:
You have to divide your data sets randomly. Scikit learn provides a function called train_test_split to do this.

- building a linear regression model using my train-test data sets.

## Residual plots
- Residual plots are a good way to visualize the errors in your data.
- your data should be randomly scattered around line zero

this would result as follows:

Conclusion
Linear regression is a basic and commonly used type of predictive analysis.
it is used to test the following:
- does a set of predictor variables do a good job in predicting an outcome (dependent) variable?
-
Which variables in particular are significant predictors of the outcome variable?
a. in what way do they–indicated by the magnitude and sign of the beta estimates–impact the outcome variable?
- The simplest form of the regression equation with one dependent and one independent variable is defined by the formula
y = c + b*xwhere:
y = estimated dependent variable score. c = constant. b = regression coefficient. x = score on the independent variable.
More on types of linear regressions
## Train/Test Split and Cross Validation in Python
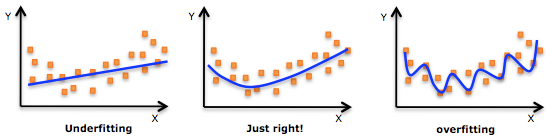
## Overfitting/Underfitting Data is usually split into two subsets:
- training data
- testing data model is fit on the train data, in order to make predictions on the test data. while doing that overfitting/underfitting might happen:
- Overfitting means that model we trained has trained “too well” and is now, well, fit too closely to the training dataset. This usually happens when the model is too complex.
- Underfitting means that the model does not fit the training data and therefore misses the trends in the data. It also means the model cannot be generalized to new data.